Einführung in den Einsatz von generativen KI-Systemen / LLMs
| Website: | Kompetenzzentrum Moodle.NRW |
| Kurs: | Lernmodul: Einführung in den Einsatz von generativen KI-Systemen / LLMs |
| Buch: | Einführung in den Einsatz von generativen KI-Systemen / LLMs |
| Gedruckt von: | Gast |
| Datum: | Dienstag, 21. Juli 2026, 22:36 |
Beschreibung
Das Lernmodul bietet einen ersten Einblick in das Thema KI und LLMs. Es wird den Fragen "Was ist Künstliche Intelligenz?" und "Was ist Prompting?" nachgegangen und die Themen "Datenschutz und Urheberrecht" sowie "Verantwortungsvolle Nutzung" werden betrachtet.
1. Kurze Einführung in KI & LLMs
Über das Lernmodul
Das Lernmodul bietet einen ersten Einblick in das Thema KI und LLMs. Es wird den Fragen "Was ist Künstliche Intelligenz?" und "Was ist Prompting?" nachgegangen und die Themen "Datenschutz und Urheberrecht" sowie "Verantwortungsvolle Nutzung" werden betrachtet. Neben allgemeinen Informationen enthält jedes Kapitel auch anwendungsbezogene, praktische Hinweise zum Umgang mit generativen KI-Systemen.
Das Lernmodul wurde von Hannah Baur an der Universität Freiburg erstellt und die Weiternutzung als OER ist ausdrücklich erlaubt. Es wurde von Moodle.NRW an das LMS Moodle angepasst und in die Buch-Aktivität überführt. Das Buch kann als Aktivität "Buch" direkt in Moodle importiert werden, einzelne Kapitel lassen sich bei Bedarf entfernen.
Inhaltsverzeichnis
- Kurze Einführung
1.1 KI-Tools im universitären Kontext
1.2 Was ist Künstliche Intelligenz?
1.3 Generative KI & LLMs
1.4 Wichtige Erkenntnisse aus diesem Kapitel - Was ist "Prompting"
2.1 Die Macht der Worte: Effektive Prompt-Erstellung
2.2 KI-Prompts - praktische Hinweise
2.3 Wichtige Erkenntnisse aus diesem Kapitel - Datenschutz und Urheberrecht
3.1 Datenschutz und personenbezogene Daten
3.2 Schutzmaßnahmen & Best Practice
3.3 Überlegungen zum Urheberrecht
3.4 Wichtige Erkenntnisse aus diesem Kapitel - Verantwortungsvolle Nutzung
4.1 Erste Ethische Überlegungen
4.2 Schattenseiten des Einsatzes von KI - Weiterführende Literatur und Quellen
5.1 Literaturverzeichnis
5.2 Abbildungs- und Literaturverzeichnis
1.1. KI-Tools im universitären Kontext
Künstliche Intelligenz (KI) unterstützt zahlreiche Prozesse in Bildung, Arbeit und Forschung. Um die Potenziale dieser Technologie effektiv nutzen zu können, ist ein kompetenter Umgang mit generativen KI-Werkzeugen sowie die Bewertung von KI-Ergebnissen entscheidend. In Zukunft wird es immer wichtiger werden, Schlüsselkompetenzen wie digitale Kompetenz (z.B. Data Literacy), Transferfähigkeit und kritisches Denken zu fördern. Diese Kompetenzen sind unerlässlich, um die Potenziale von generativer KI optimal zu nutzen und gleichzeitig ihre Grenzen zu erkennen. Bildungseinrichtungen müssen diese Kompetenzen gezielt fördern, um einen verantwortungsvollen Umgang mit generativen KI-Technologien zu gewährleisten.

Abb. 1: Hanna Barakat & Cambridge Diversity Fund / Better Images of AI / Data Lab Dialogue / CC-BY 4.0
1.2. Was ist Künstliche Intelligenz?
![]() Auf dieser und der folgenden Seite werden die Grundlagen der KI-Technologie erläutert und einzelne wichtige Begriffe erklärt.
Auf dieser und der folgenden Seite werden die Grundlagen der KI-Technologie erläutert und einzelne wichtige Begriffe erklärt.
Künstliche Intelligenz (KI) ist eine Technologie, die es Maschinen ermöglicht, menschliche Intelligenz nachzuahmen und sie um Fähigkeiten wie logisches Denken, Erinnern, Kreativität und Lernen erweitert. KI lässt sich als eine hochentwickelte Analysemethode verstehen, die enorme Datenmengen verarbeitet, um Muster zu erkennen und präzise Vorhersagen zu treffen. Diese Daten können vielfältig sein und reichen von Filmen und Bildern bis hin zu Texten und menschlichen Gesichtern (Schmid, 2022; Röhler 2020).
In der Regel werden KI-Anwendungen je nach Aufgabenumfang in zwei Kategorien eingeteilt:
Schwache KI ist auf ein spezifisches Fachgebiet spezialisiert, während starke KI gleiche oder ähnliche intellektuelle Fähigkeiten wie ein Mensch anstrebt.
Die schwache KI, auch als methodische KI bezeichnet, ist auf spezifische Aufgaben spezialisiert. Sie besitzt keine eigenständige Kreativität oder die Fähigkeit, universell zu lernen. Stattdessen konzentriert sie sich auf:
- Das Trainieren von Erkennungsmustern (Machine Learning)
- Das Abgleichen und Durchsuchen großer Datenmengen
- Die Bewältigung klar definierter, wiederkehrender Probleme
Beispiele für schwache KI sind Sprachassistenten wie Alexa oder Siri, Navigationssysteme und Anwendungen zur Text- und Bilderkennung.
Die starke KI hingegen strebt danach, die menschliche Intelligenz in ihrer Gesamtheit nachzubilden. Sie soll in der Lage sein:
- Selbstständig Aufgaben zu erkennen und zu definieren
- Sich eigenständig Wissen anzueignen und aufzubauen
- Kreative Lösungen für komplexe Probleme zu finden
Während schwache KI bereits in vielen Bereichen des alltäglichen Lebens eingesetzt wird, befindet sich die Entwicklung starker KI noch in einem frühen Stadium und ist hauptsächlich Gegenstand der Forschung (Stadler, 2023; thws, 2024).
Video 1: Eine kurze Geschichte der KI. Lernende Systeme, die Plattform für Künstliche Intelligenz, 2020.
1.3. Wie ist KI aufgebaut?
Um die Ziele der Mustererkennung, der präzisen Vorhersage und der Nachahmung menschlicher Intelligenz zu erreichen, verwendet die KI verschiedene Techniken, wobei Machine Learning und Deep Learning eine zentrale Rolle spielen.
Machine Learning ist ein Teilbereich der künstlichen Intelligenz, der es Systemen ermöglicht, automatisch aus Erfahrungen zu lernen und sich zu verbessern. Es verwendet Algorithmen, um Daten zu analysieren und daraus fundierte Entscheidungen zu treffen. ML kann Wissen generieren, Zusammenhänge erkennen und unbekannte Muster identifizieren. Dieses Wissen kann auf neue, unbekannte Datensätze angewendet werden, um Vorhersagen zu treffen und Prozesse zu optimieren. Machine Learning wird z.B. in der Werbung (Produktempfehlungen, Verhaltensprognosen), in der IT-Sicherheit (Erkennung von Kreditkartenbetrug/Malware), in der Wissenschaft und in der Medizin eingesetzt (Wuttke, 2023).
Deep Learning ist eine spezielle Methode der Informationsverarbeitung und ein wichtiger Teilbereich sowohl des Machine Learning als auch der künstlichen Intelligenz. Zur Analyse großer Datensätze verwendet Deep Learning neuronale Netze, die ähnlich wie das menschliche Gehirn funktionieren. Die Daten werden zunächst extrahiert und dann analysiert, um eine Schlussfolgerung oder Vorhersage zu treffen. Der mehrschichtige Aufbau dieser neuronalen Netze ermöglicht das automatisierte Lernen komplexer Muster und Darstellungen aus Daten und wird beispielsweise in der Bilderkennung, beim autonomen Fahren oder der Spracherkennung eingesetzt (Nopp, 2019; Delua, 2021).
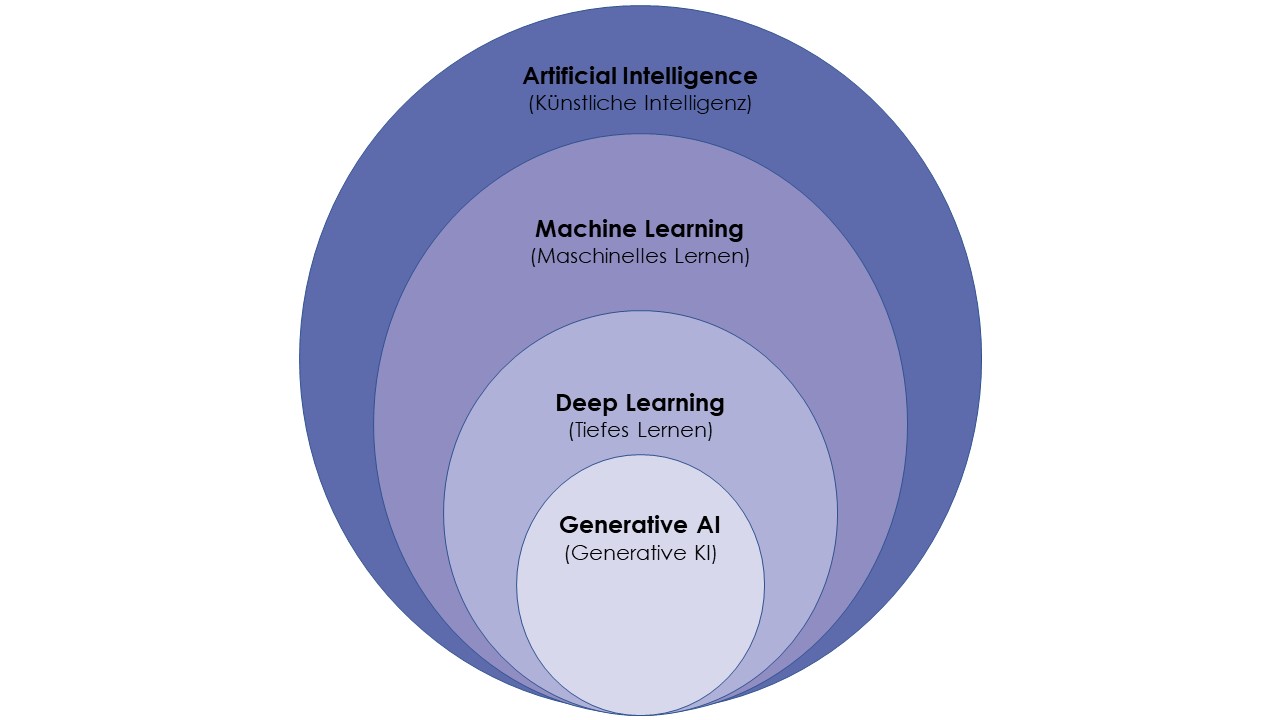
Abb. 2: Komponenten der KI. Nach: Introduction to Generative AI, Apress, Seite 3. Applied Generative AI for Beginners. Kulkarni et al, 2023.
1.4. Generative KI & LLMs
Bei der Generativen KI handelt es sich um eine Unterart der Künstlichen Intelligenz, die auf die Generierung von Daten oder Inhalten spezialisiert ist, anstatt sich auf die Analyse vorgegebener Muster oder Informationen zu beschränken. Solche KI-Systeme werden in Bereichen wie Kunst, Design und Contenterstellung eingesetzt (Luber, 2023).
Large Language Models (LLMs) und generative KI sind eng miteinander verbunden, aber nicht identisch. LLMs sind eine spezialisierte Untergruppe der generativen KI, die sich auf die Verarbeitung und Erzeugung natürlicher Sprache konzentriert.
Der Hauptunterschied liegt in ihrem Anwendungsbereich:
LLMs fokussieren sich auf textbasierte Aufgaben wie Sprachverständnis und Textgenerierung, während generative KI auch andere Medienformate wie Bilder, Videos und Musik erzeugen kann (Koleva, 2023). Das derzeit bekannteste LLM ist ChatGPT. Die Popularität der generativen KI ist auf ihre Benutzerfreundlichkeit zurückzuführen, die es Benutzer*innen ermöglicht, auf einfache Weise mit der KI zu kommunizieren (Ninetwothree, 2023). Wie generative KI und spezifisch ChatGPT funktionieren, zeigen die beiden Videos unten.
![]() Wichtig zu wissen:
Wichtig zu wissen:
Textgenerative KI-Tools haben nach dem Training keinen Zugriff mehr auf ihre ursprünglichen Trainingsdaten und können daher keine Quellen direkt nachschlagen, abschreiben oder zitieren. Sie verarbeiten zwar viele Textdokumente während des Trainings, können jedoch keine spezifischen Zitate bereitstellen. Einige moderne LLMs können jedoch durch Internetzugang auf externe Wissensdatenbanken zugreifen und damit Informationen in Echtzeit abrufen.
1.5. Wichtige Erkenntnisse aus diesem Kapitel
-
Derzeit verwendete KI Modelle sind der sogenannten Schwachen KI zuzuordnen, beschränken sich auf spezifische Aufgaben und werden bereits im privaten Alltag eingesetzt. Starke KI bezieht sich auf Systeme mit menschenähnlicher Intelligenz und Selbstbewusstsein (einschließlich Emotionen und Moral) und existiert derzeit noch nicht.
-
Maschinelles Lernen (ML) wird unterteilt in Überwachtes Lernen, Unüberwachtes Lernen, Bestärkendes Lernen und Evolutionäres Lernen und ist ein Teilgebiet der KI, das Computern ermöglicht ohne explizite Programmierung Muster in Daten zu erkennen. Es wird bei Produktempfehlungen, der Prognose von Kundenverhalten und der Erkennung von Kreditkartenbetrug eingesetzt.
-
Deep Learning (DL) ist ein Teilgebiet des ML, das sich auf Künstliche Neuronale Netze und große Datenmengen konzentriert und komplexe Aufgaben löst. Es wird eingesetzt, um Bilder zu erkennen, Texte zu verstehen und präzise Entscheidungen zu treffen.
-
Generative KI ist eine künstliche Intelligenz, die auf die Generierung von Daten oder Inhalten spezialisiert ist wie die Erstellung von Texten, Bildern, Musik, Audio und Videos.
- LLMs sind eine spezialisierte Untergruppe der generativen KI, die sich auf die Verarbeitung und Erzeugung natürlicher Sprache konzentriert.

![]() Sogenannte "Prompts" (die Eingabeaufforderung) sind wichtig für den sinnvollen Einsatz von generativen KI-Modellen. Im nächsten Kapitel widmen wir uns diesem Thema und geben Ihnen hilfreiche Tipps für die Erstellung effektiver Prompts.
Sogenannte "Prompts" (die Eingabeaufforderung) sind wichtig für den sinnvollen Einsatz von generativen KI-Modellen. Im nächsten Kapitel widmen wir uns diesem Thema und geben Ihnen hilfreiche Tipps für die Erstellung effektiver Prompts.
2. Was ist "Prompting"
Das Kapitel thematisiert den Einsatz von generativen KI-Modellen für die Inhalterstellung, insbesondere die Bedeutung und effektive Verwendung von Prompts. Prompts sind kurze Anweisungen, die die Qualität und Relevanz der von KI-Modellen generierten Texte stark beeinflussen. Die Bedeutung des guten Prompt-Engineering wird hervorgehoben. Darüber hinaus enthält es Praxistipps zur effektiven Prompterstellung.
2.1. Die Macht der Worte: Effektive Prompt-Erstelllung
![]() In diesem Kapitel erklären wir Ihnen in Kürze, warum Prompts wichtig sind und was Sie beim Prompting beachten sollten.
In diesem Kapitel erklären wir Ihnen in Kürze, warum Prompts wichtig sind und was Sie beim Prompting beachten sollten.
Generative KI-Modelle haben die Erstellung von Inhalten revolutioniert, indem sie komplexe und kreative Texte generieren, die oft von menschlichen Erzeugnissen kaum zu unterscheiden sind. Der Schlüssel zur effektiven Nutzung dieser Modelle liegt in der Verwendung von Prompts.
Ein Prompt ist eine kurze Anweisung, die dem KI-Modell gegeben wird, um eine gewünschte Ausgabe zu erhalten.
Prompts dienen als Ausgangspunkt für verschiedene Anwendungen wie Ideengenerierung, Texterstellung, Übersetzungen und Beantwortung von Fragen (Mascellino, 2023).
Die Qualität des generierten Inhalts hängt stark von der Präzision und Spezifität des Prompts ab. Durch geschickte Prompt-Gestaltung können Nutzende die Ergebnisse steuern und optimieren, was die Leistungsfähigkeit dieser fortschrittlichen Technologien unterstreicht (Gimpel et al 2023).
 KI ist keine Suchmaschine
KI ist keine Suchmaschine
Beim ersten Kontakt mit großen Sprachmodellen (LLMs) wie ChatGPT neigen viele dazu, die gewohnte Suchmaschinen-Mentalität anzuwenden und einfache Faktenfragen zu stellen, wie zum Beispiel: „Wann starb Johann Sebastian Bach?"
Obwohl einige KI-Modelle solche Fragen beantworten können, ist es wichtig zu beachten, dass nicht alle Modelle gleich funktionieren. Manche KI-Systeme neigen dazu, Informationen zu "halluzinieren", also falsche Angaben zu machen, wenn sie die korrekte Antwort nicht kennen. Anstatt zuzugeben, dass sie eine Information nicht haben, könnten sie unzuverlässige oder erfundene Antworten liefern.
Der Grund dafür liegt in der Art und Weise, wie diese Modelle trainiert werden:
Sie basieren auf Wahrscheinlichkeitsberechnungen und generieren Texte, die statistisch plausibel erscheinen, basierend auf den Mustern in den Trainingsdaten.
Wenn ihnen jedoch Informationen fehlen oder die Anfrage unklar ist, versuchen sie trotzdem, eine Antwort zu formulieren – oft ohne explizit anzugeben, dass sie unsicher sind oder keine Daten dazu haben. Um das volle Potenzial der KI auszuschöpfen und zuverlässigere Antworten zu erhalten, ist es ratsam, kontextbezogene oder kreativere Anfragen zu stellen. Ein konstruktiver Ansatz könnte beispielsweise lauten:
„Nenne mir zwei wichtige Lebensstationen von Johann Sebastian Bach und erkläre, warum sie bedeutend waren."
Solche kontextbezogenen Prompts regen die KI dazu an, nicht nur Fakten aufzuzählen, sondern auch Verbindungen herzustellen, Zusammenhänge zu erläutern oder Inhalte in einem breiteren Rahmen zu präsentieren. Dies führt oft zu reichhaltigeren und nützlicheren Antworten. Durch präzise und klare Fragen oder Anweisungen lenkt man den Textgenerator in die richtige Richtung und ermöglicht es ihm, genaue und relevante Antworten zu generieren.
2.2. KI-Prompts - Praktische Hinweise
Die Antworten von Chatbots sind nur so gut wie die Befehle, die sie erhalten (Winter, 2023). Wir erklären Ihnen, worauf Sie bei der Erstellung von Prompts achten müssen.
Übung: Wir empfehlen Ihnen, die Beispielprompts parallel zum Lesen selbst auszuprobieren. Dazu eignen sich alle textgenerierenden KIs wie Chat GPT, llama, Mistral etc.
 Tipps für die Erstellung von Prompts
Tipps für die Erstellung von Prompts
Die 5 besten Prompt Engineering Tipps in nur 5 Minuten.
Video 6: Die 5 besten Prompt Engineering Tipps in nur 5 Minuten. Quelle: Datasolut, 2024
Weiterführende Links
Offener Prompt-Katalog des KI-Campus
Der Prompt-Katalog bietet eine Sammlung geprüfter Prompts für die Hochschullehre. Er zeigt Beispiele erfolgreicher KI-Anwendungen mit kurzen Kontextbeschreibungen. Lehrende können den Katalog zur Recherche, Inspiration oder Übernahme von Prompt-Strategien nutzen.
Prompt-Labor
Möchten Sie Ihre Prompting-Kenntnisse vertiefen? Der KI-Campus bietet das Prompt-Labor an, das eine Einführung in die Grundlagen des Promptings gibt und Funktionsweisen sowie Fallstricke im Umgang mit KI behandelt.
2.3. Wichtige Erkenntnisse aus diesem Kapitel
- Prompts sind kurze Anweisungen oder Eingabeaufforderungen, die einem KI-Modell gegeben werden, um eine gewünschte Ausgabe zu erhalten. Sie dienen als Ausgangspunkt für die Generierung von Inhalten.
- Die Qualität und Genauigkeit einer KI-Ausgabe hängt von vielen Faktoren ab. Zu den wichtigsten Kriterien gehören die Bereitstellung von Kontext- und Hintergrundinformationen sowie die Genauigkeit und Klarheit der Anweisungen.

![]() Wichtige Informationen zum Datenschutz und zum verantwortungsvollen Einsatz von KI finden Sie im nächsten Kapitel.
Wichtige Informationen zum Datenschutz und zum verantwortungsvollen Einsatz von KI finden Sie im nächsten Kapitel.
3. Datenschutz und Urheberrecht
Das Kapitel behandelt wichtige Aspekte des Datenschutzes im Zusammenhang mit der Nutzung von KI und LLMs, insbesondere im Hinblick auf den Schutz personenbezogener Daten und die Einhaltung der Datenschutzgrundverordnung (DSGVO). Es wird erörtert, welche Arten von Daten als personenbezogen gelten und wie diese bei der Nutzung von KI-Systemen verarbeitet werden können, was verschiedene Datenschutzrisiken birgt, wie Profiling, Datenverarbeitung in Drittländern und die mögliche unerlaubte Weiterverwendung der Daten. Zudem werden praxisnahe Hinweise zur Risikominimierung gegeben, darunter das Lesen der Datenschutzbestimmungen bei der Nutzung externer Dienste und der umsichtige Umgang mit den Ausgaben von KI-Systemen.
3.1. Datenschutz & personenbezogene Daten
![]() Dieses Kapitel bietet grundlegende Informationen zum Datenschutz und zeigt auf, wie KI und LLM verantwortungsvoll eingesetzt werden können. Insbesondere im Hinblick auf den Schutz personenbezogener Daten und die Einhaltung gesetzlicher Vorschriften.
Dieses Kapitel bietet grundlegende Informationen zum Datenschutz und zeigt auf, wie KI und LLM verantwortungsvoll eingesetzt werden können. Insbesondere im Hinblick auf den Schutz personenbezogener Daten und die Einhaltung gesetzlicher Vorschriften.
KI-Kompetenz bedeutet auch Datenschutzkompetenz
Im Rahmen unserer Schulung zur Nutzung von KI-Werkzeugen an der Universität ist ein klares Verständnis für das Konzept der personenbezogenen Daten unerlässlich.
Was sind personenbezogene Daten?
Personenbezogene Daten sind nach der Datenschutzgrundverordnung (DSGVO) alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person beziehen. Dazu zählen zum Beispiel:
-
Identifikationsdaten: Name, Adresse, Geburtsdatum, E-Mail-Adresse
-
Kontaktdaten: Telefonnummer, Kommunikationsverläufe
-
Studien- und Leistungsdaten: Matrikelnummer, Noten, Studienverlauf
- Sensible Daten: Gesundheitsdaten, ethnische Herkunft, politische Meinungen
Auch indirekte Informationen, die in Kombination mit anderen Daten zur Identifizierung einer Person führen können, fallen darunter. Dazu kommt es auch darauf an, welches Zusatzwissen bei dem*der jeweiligen Empfänger*in oder der datenverarbeitenden Organisation vorhanden ist oder beschafft werden kann. Die Definition ist also sehr weit gefasst.
Relevanz für die Nutzung von KI-Systemen und LLMs
Bei der Nutzung von KI-Systemen werden in der Regel Daten übermittelt, etwa bei der Registrierung oder durch die Verarbeitung von Eingaben. Dabei ist oft unklar, ob und wie sich der Anbieter an die Datenschutzgrundverordnung (DSGVO) hält. In diesem Zusammenhang ergeben sich folgende Datenschutzrisiken:
- Datenverarbeitung in Drittländern:
Teilweise verarbeiten KI-Anbieter Daten außerhalb der EU oder des EWR, in Ländern, die keinen vergleichbaren Datenschutzstandard wie die DSGVO bieten. Das hat insbesondere zur Folge, dass Dritte wie Regierungsorganisationen oder Geheimdienste auf die Daten zugreifen können und Betroffene die Rechte, die ihnen nach den europäischen Datenschutzgesetzen in diesem Zusammenhang zustehen, nicht oder nur unzureichend geltend machen können.
- Profiling:
Für die Nutzung von KI-Systemen ist oft eine Registrierung erforderlich, bei der Anmeldedaten und möglicherweise Zahlungsinformationen angegeben werden müssen. Diese Daten könnten mit den Eingabedaten kombiniert und zur Erstellung von persönlichen Profilen über die User genutzt werden. Diese Profile können zum Beispiel an Werbenetzwerke weitergegeben werden.
- Weitere Nutzung für eigene Zwecke:
Es besteht die Gefahr, dass eingegebene Daten von den Anbietenden eingesehen und für eigene Zwecke, beispielsweise zum Training der Modelle, genutzt werden. Die Folge davon kann sein, dass eingegebene private Daten bei Anfragen anderer Nutzender vom Modell ausgegeben werden.
- Eingeschränkte Geltendmachung von Betroffenenrechten:
Die Rechte von Nutzenden oder Personen, deren Daten in das System eingeben werden, wie das Recht auf Auskunft, Berichtigung oder Löschung personenbezogener Daten, sind insbesondere bei Anbietenden aus Drittländern oft schwer durchzusetzen. Das liegt zum einen an der Rechtslage, aber auch an Aufbau und Funktionsweise der Modelle selbst.
- Mangelnde Informations- und Transparenzpflichten:
Viele Anbietende von KI-Systemen informieren nicht ausreichend darüber, wie Daten verarbeitet werden, welche Zwecke die Verarbeitung verfolgt und welche Rechte den Nutzenden zustehen. Dies erschwert es, informierte Entscheidungen zu treffen und kann zu einem Risiko für die Datenschutzrechte der Betroffenen werden. Auch mangelnde Anonymisierung durch Nutzende und unbeabsichtigte Ausgaben personenbezogener Daten durch das Modell stellen Risiken dar. Der Einsatz von innovativen Technologien wie KI-Anwendungen setzt einen kritisch-reflexiven und verantwortungsbewussten Umgang der Nutzenden voraus.
Praktische Hinweise zur Risikominimierung:
-
Lesen Sie bei intern angebotenen Systemen die Nutzungsbedingungen oder einschlägigen Richtlinien sorgfältig durch und halten Sie die Vorgaben ein.
-
Geben Sie nur unbedingt erforderliche Informationen ein und verzichten Sie auf die Weitergabe sensibler Informationen wie Betriebs- und Geschäftsgeheimnisse. Das gilt für Ihre eigenen Daten und die Daten der Universität sowie für Daten Dritter oder anderer Organisationen.
- Daten, wie Forschungsdaten ohne Personenbezug, dürfen nur genutzt werden, wenn entsprechende Nutzungsrechte vorliegen, das Urheberrecht beachtet wird und keine Geheimhaltungsvereinbarungen oder ähnliches im Wege stehen.
Bei externen Anbietenden gilt außerdem:
-
Lesen Sie die Nutzungsbestimmungen bzw. Allgemeinen Geschäftsbedingungen (AGB) und Datenschutzerklärungen sorgfältig und prüfen Sie, ob der Dienst den DSGVO-Vorgaben entspricht, bevor Sie ihn nutzen.
-
Schließen Sie, wenn möglich, die weitere Verarbeitung durch Anbietende zu eignen Zwecken aus (Training und Profiling).
- Verwenden Sie bei der Registrierung eine anonymisierte E-Mail-Adresse und geben Sie möglichst wenige Daten von sich an.
Umgang mit Ausgaben von KI-Systemen
- Auch KI-Systeme können personenbezogene Daten generieren. In der Regel fehlt jedoch die rechtliche Grundlage, diese Daten weiterzuverarbeiten, etwa zu speichern oder zu veröffentlichen. Dies gilt vor allem im dienstlichen Kontext. Bei Daten von Personen des öffentlichen Lebens (z.B. Prominenten) kann im Einzelfall ein überwiegendes berechtigtes Interesse an der Verarbeitung bestehen. Dies setzt nach der derzeit geltenden Rechtsprechung jedoch voraus, dass die Daten aus öffentlich zugänglichen Quellen stammen und ein öffentliches Interesse an ihrer Kenntnis besteht. Da die Herkunft von KI-generierten Daten in der Regel unklar ist, sollten diese besonders vorsichtig behandelt werden. Die DSGVO sieht derzeit keine spezifischen Ausnahmen für solche Daten vor, unabhängig davon, ob sie theoretisch aus öffentlichen Quellen stammen könnten. Wie sich die Rechtslage hier entwickelt, bleibt abzuwarten. Daher gilt: Grundsätzlich keine personenbezogenen Daten aus den Ausgaben übernehmen!
Weitere praktische Hinweise zum Umgang mit Ausgaben:
-
Prompts sollten so formuliert werden, dass keine personenbezogenen Daten explizit angefragt oder verarbeitet werden. Tipps zum „Datenschutzfreundlichen Prompten“ erhalten Sie auf der nächsten Seite.
-
Überprüfen Sie die generierten Inhalte sorgfältig, um sicherzustellen, dass keine personenbezogenen oder sonstigen sensiblen Informationen enthalten sind.
- Nutzen Sie nur Inhalte, die keine personenbezogenen Daten enthalten. Löschen Sie Chats, wenn personenbezogene Daten generiert wurden, am Ende der Sitzung.
Bewusstsein für KI-Limitationen
Generative KI-Anwendungen, die auf LLMs beruhen, sind nicht darauf ausgelegt, die „richtige“ Antwort zu geben. Sie wurden entwickelt, um auf sprachlicher Ebene mit uns Menschen zu interagieren. Die Antworten basieren auf Wahrscheinlichkeits-Modellen, die sie aus großen Mengen von Trainingsdaten gelernt haben und werden durch die Berechnung der wahrscheinlichsten nächsten Wörter generiert. Beachten Sie in diesem Zusammenhang, dass generative KI-Systeme Inhalte erstellen, die fehlerhaft oder ungenau sein können. Prüfen Sie alle generierten Informationen und passen Sie diese gegebenenfalls an, bevor sie diese übernehmen.
 Besonders wichtig:
Besonders wichtig:
Beim Einsatz von KI in Verwaltung, Forschung Lehre und Studium ist der Schutz personenbezogener Daten entscheidend, um die eigene sowie die Privatsphäre der Betroffenen zu wahren.
3.2. Schutzmaßnahmen & Best Practice
![]() Beim Einsatz von generativen KI-Systemen ist es entscheidend, sicherzustellen, dass keine sensiblen Informationen preisgegeben werden. In diesem Kapitel erfahren Sie, wie Sie datenschutzsicher prompten und welche Best Practices Ihnen helfen, Ihre Privatsphäre zu wahren.
Beim Einsatz von generativen KI-Systemen ist es entscheidend, sicherzustellen, dass keine sensiblen Informationen preisgegeben werden. In diesem Kapitel erfahren Sie, wie Sie datenschutzsicher prompten und welche Best Practices Ihnen helfen, Ihre Privatsphäre zu wahren.
Datenschutzfreundliches Prompten
- Keine Eingabe von personenbezogenen Daten:
Vermeiden Sie Namen, Adressen, Geburtsdaten, Telefonnummern oder andere identifizierende Informationen in den Prompts.
- Datenminimierung:
Geben Sie nur die notwendigen Informationen an und vermeiden Sie unnötige Details, die Rückschlüsse auf spezifische Personen, Gruppen oder Situationen ermöglichen könnten. Vermeiden Sie die Erwähnung externer Referenzen wie Projektnamen, spezifischer Referenznummern oder anderer spezifischer Systemdaten.
- Abstraktion von Kontextinformationen:
Verwenden Sie nur den minimal notwendigen Kontext und abstrahieren Sie präzise Details, um potenzielle Identifikatoren zu minimieren. Wo immer möglich, sollten Daten anonymisiert oder pseudonymisiert werden, um die Identifizierbarkeit von Personen zu vermeiden.
- Verwendung generischer Rollen, Titel oder Pseudonyme:
Statt Namen nutzen Sie allgemeine Titel oder Rollen, wie „Mitarbeiter*in“, „Kunde*Kundin“ oder „Student*in“. Dadurch bleiben Antworten allgemein und weniger persönlich. Wenn spezifische Informationen unvermeidlich sind, ersetzen Sie sie durch Pseudonyme oder Platzhalter wie „Person A“ oder „Frau X“.
- Allgemeine Formulierung des Prompts:
Bitten Sie die KI am Beginn der Session, nur allgemeine Antworten zu generieren, um sicherzustellen, dass die Ausgaben keine personenbezogenen Daten enthalten (z.B. „Gib nur allgemeine Antworten ohne personenbezogene Daten“). Unter Umständen muss die Vorgabe mehrfach wiederholt werden.
- Vermeiden von Standort- und Zeitangaben:
Falls möglich, keine genauen Orte oder Zeiten in den Prompts verwenden. Statt eines Datums etwa „im Sommer 2024“ oder „vor kurzem“ angeben.
Datenschutzfreundlicher Umgang mit Ausgaben
- Sorgfältige Prüfung der Ausgabe:
Überprüfen Sie die Antworten auf eventuell enthaltene personenbezogene Daten, bevor Sie sie weiterverarbeiten oder teilen.
- Anonymisierung und Pseudonymisierung der Ausgabe:
Falls die KI personenbezogene Daten generiert, entfernen oder pseudonymisieren Sie diese vor der Weitergabe. Löschen Sie den Chatverlauf am Ende der Session.
![]() Beim Einsatz von generativer KI und LLM in universitären Prozessen ist es wichtig, diese Grundsätze zu beachten, um die Rechte der Betroffenen zu wahren und das Vertrauen in die Institution zu stärken.
Beim Einsatz von generativer KI und LLM in universitären Prozessen ist es wichtig, diese Grundsätze zu beachten, um die Rechte der Betroffenen zu wahren und das Vertrauen in die Institution zu stärken.
3.3. Überlegungen zum Urheberrecht
![]() Der Einsatz von generativen KI-Systemen wirft eine Reihe von urheberrechtlich problematischen Aspekten auf. Im Folgenden werden einige Überlegungen und drei Praxisbeispiele zur Veranschaulichung dieser Problematik vorgestellt.
Der Einsatz von generativen KI-Systemen wirft eine Reihe von urheberrechtlich problematischen Aspekten auf. Im Folgenden werden einige Überlegungen und drei Praxisbeispiele zur Veranschaulichung dieser Problematik vorgestellt.
- Verwendung von Trainingsdaten:
Viele KI-Modelle werden mit großen Datenmengen trainiert, die urheberrechtlich geschützte Werke enthalten. Die Frage, ob die Verwendung solcher Daten für das Training rechtlich zulässig ist, ist derzeit noch umstritten und kann zu rechtlichen Konflikten führen.
- Plagiate und geistiger Diebstahl:
Wenn Nutzer*innen KI-generierte Inhalte in eigene Werke wie z.B. Hausarbeiten, Abschlussarbeiten oder wissenschaftliche Aufsätze integrieren, besteht die Gefahr, dass sie nicht nur Urheberrechtsverletzungen begehen, weil die Urheberrechte Dritter unerkannt bleiben, sondern aufgrund fehlender Quellenangaben in ihrer Arbeit auch Plagiate begehen, ohne sich dessen bewusst zu sein.
- Rechte am Output der KI:
Generative KI-Systeme erzeugen Inhalte, die auf bestehenden urheberrechtlich geschützten Materialien basieren. Häufig ist unklar, ob der Output einer KI Teile urheberrechtlich geschützter Werke enthält und daher grundsätzlich nur mit Zustimmung der Urhebenden verwendet werden darf, oder ob es sich bei dem Output um ein ausschließlich abgeleitetes Werk handelt, das urheberrechtlich nicht geschützt ist und daher frei verwendet werden darf.
Praktische Beispiele
- Texterstellung
Eine Person nutzt ein KI-gestütztes Textgenerierungstool, um einen Artikel für eine wissenschaftliche Veröffentlichung zu erstellen. Dabei könnte das Tool Passagen aus urheberrechtlich geschützten Texten übernehmen, was zu einem Plagiatsvorwurf führen könnte, selbst wenn die Nutzenden dies nicht beabsichtigt haben.
- Bilderzeugung
Ein Künstler verwendet eine KI, um neue Kunstwerke zu schaffen, die stark von bestehenden, urheberrechtlich geschützten Bildern inspiriert sind. Wenn die erzeugten Werke Ähnlichkeiten mit den Originalen aufweisen, könnte dies zu rechtlichen Auseinandersetzungen über Urheberrechtsverletzungen führen.
- Musikkompositionen
Eine Musikerin nutzt ein KI-Tool zur Komposition von Musikstücken. Wenn die KI auf einer Vielzahl von urheberrechtlich geschützten Musikstücken trainiert wurde, besteht das Risiko, dass die generierte Musik Melodien oder Harmonien enthält, die als Plagiat angesehen werden können.
![]() Diese Beispiele zeigen die Bedeutung urheberrechtlicher Fragen bei generativer KI. Um rechtliche Probleme zu vermeiden und Rechte zu respektieren, sollten beim Einsatz KI-generierter Inhalte folgende Vorsichtsmaßnahmen beachtet werden:
Diese Beispiele zeigen die Bedeutung urheberrechtlicher Fragen bei generativer KI. Um rechtliche Probleme zu vermeiden und Rechte zu respektieren, sollten beim Einsatz KI-generierter Inhalte folgende Vorsichtsmaßnahmen beachtet werden:
Bearbeitung des KI-Outputs: Um mögliche Urheberrechtsverletzungen zu vermeiden, sollten Sie den KI-generierten Inhalt vor der Veröffentlichung bearbeiten und mit eigenen kreativen Elementen anreichern.
Beschränkung auf private Nutzung: Wenn Sie sich nicht sicher sind, ob ein generierter Output gegen das Urheberrecht verstößt, können Sie ihn dennoch privat nutzen, solange er nicht offensichtlich rechtswidrig hergestellt wurde.
Vorsicht bei öffentlicher Nutzung: Vermeiden Sie die Veröffentlichung oder kommerzielle Nutzung von KI-generierten Inhalten, wenn Sie sich nicht sicher sind, ob Urheberrechte verletzt werden könnten.
![]()
- Inhalte, die mit KI erstellt wurden, müssen gekennzeichnet werden
- Gegebenenfalls muss erklärt werden, für welchen Arbeitsschritt welches System wie eingesetzt wurde. Dies ist nicht nur als Information für die prüfende Person zu verstehen, sondern auch als Reflexionsinstrument für Sie selbst.
Durch die Einhaltung dieser Vorsichtsmaßnahmen und den umsichtigen Umgang mit KI-generierten Inhalten kann das Risiko von Urheberrechtsverletzungen bei der Nutzung von KI-Werkzeugen minimiert werden.
3.4. Wichtige Erkenntnisse aus diesem Kapitel
![]()
-
Personenbezogene Daten sind nach der Datenschutzgrundverordnung (DSGVO) alle Informationen, die sich auf eine identifizierte oder identifizierbare natürliche Person beziehen.
-
Beim Einsatz von KI in Verwaltung, Forschung Lehre und Studium ist der Schutz personenbezogener Daten entscheidend, um die eigene sowie die Privatsphäre der Betroffenen zu wahren.
-
Es ist wichtig, sich der urheberrechtlichen Fragen beim Einsatz generativer KI-Systeme bewusst zu sein. Um rechtliche Probleme zu vermeiden und die Rechte anderer zu respektieren, sollten bei der Nutzung von KI-generierten Inhalten Vorsichtsmaßnahmen getroffen werden (Prüfung und Überarbeitung des KI-Outputs, Vorsicht bei der Veröffentlichung KI-generierter Inhalte bzw. Beschränkung auf private Nutzung).
-
Generell gilt: Inhalte, die mit KI erstellt wurden, müssen gekennzeichnet werden. Gegebenenfalls muss erklärt werden, für welchen Arbeitsschritt welches System wie eingesetzt wurde. Dies ist nicht nur als Information für die prüfende Person zu verstehen, sondern auch als Reflexionsinstrument für Sie selbst!
![]() Im nächsten Kapitel liegt der Fokus darauf, Kompetenzen zu stärken, die eine ethische Reflexion ermöglichen und helfen, KI-Ergebnisse zu erkennen und zu bewerten. Zudem werden die Grenzen und Herausforderungen des KI-Einsatzes beleuchtet.
Im nächsten Kapitel liegt der Fokus darauf, Kompetenzen zu stärken, die eine ethische Reflexion ermöglichen und helfen, KI-Ergebnisse zu erkennen und zu bewerten. Zudem werden die Grenzen und Herausforderungen des KI-Einsatzes beleuchtet.
4. Verantwortungsvolle Nutzung
Dieses Kapitel diskutiert die ethischen Aspekte und Herausforderungen beim Einsatz generativer KI-Anwendungen an Hochschulen. Insbesondere wird die Notwendigkeit eines umfassenden Bewusstseins für Datenschutz, Diskriminierungsfreiheit und die Sicherstellung der Datensouveränität der Nutzenden in den Blick genommen. Zudem wird die Vermittlung von digitalen und ethischen Kompetenzen diskutiert, um zukünftige Technologien verantwortungsvoll einsetzen zu können.
4.1. Erste Ethische Überlegungen
![]() Ein verantwortungsvoller Umgang mit dem Einsatz von generativen KI-Anwendungen als Arbeitsmittel oder Lerninhalt an Hochschulen setzt ethische Überlegungen voraus. Dazu gehören ein Bewusstsein für die Stärken und Schwächen von KI-Tools, die Sicherstellung der Datensouveränität der Nutzer*innen, der Schutz vor Diskriminierung sowie klare Spezifikationen und Evaluationsverfahren. Zudem ist die umfassende Information und Einbeziehung aller Nutzer*innen solcher Systeme notwendig. Die Vermittlung digitaler Kompetenzen in Bezug auf generativer KI sollte daher immer mit der Förderung ethischer Haltungen und Fähigkeiten einhergehen.
Ein verantwortungsvoller Umgang mit dem Einsatz von generativen KI-Anwendungen als Arbeitsmittel oder Lerninhalt an Hochschulen setzt ethische Überlegungen voraus. Dazu gehören ein Bewusstsein für die Stärken und Schwächen von KI-Tools, die Sicherstellung der Datensouveränität der Nutzer*innen, der Schutz vor Diskriminierung sowie klare Spezifikationen und Evaluationsverfahren. Zudem ist die umfassende Information und Einbeziehung aller Nutzer*innen solcher Systeme notwendig. Die Vermittlung digitaler Kompetenzen in Bezug auf generativer KI sollte daher immer mit der Förderung ethischer Haltungen und Fähigkeiten einhergehen.
Datensouveränität und Datenschutz:
Hochschulen müssen sicherstellen, dass die Privatsphäre und der Schutz persönlicher Daten gewährleistet sind. Studierende und Mitarbeitende müssen Kontrolle über ihre Daten haben, und es sollte Transparenz darüber herrschen, wie Daten von generativen KI-Systemen genutzt werden.
Diskriminierungsfreiheit:
Generative KI-Anwendungen dürfen keine Benachteiligung aufgrund von Geschlecht, Herkunft, sozialem Status oder anderen diskriminierenden Faktoren fördern. Dies erfordert eine sorgfältige Prüfung der Daten, mit denen generative KI-Systeme trainiert werden, sowie eine kontinuierliche Überwachung auf potenzielle Verzerrungen. Insbesondere ist eine Sensibilisierung für Bias in Sprachmodellen wichtig, um sicherzustellen, dass diese Modelle nicht unbeabsichtigt bestehende Vorurteile verstärken (siehe Risiken & Grenzen).
Einbeziehung und Aufklärung der Nutzer*innen:
Alle Betroffenen – ob Studierende, Lehrende oder Mitarbeitende – sollten über die Funktionsweise und die Implikationen von generativen KI-Anwendungen informiert und geschult werden. Nur so können sie fundierte Entscheidungen über die Nutzung treffen und Risiken erkennen.
Klare Spezifikationen und Evaluationsprozeduren:
Um sicherzustellen, dass generative KI-Systeme zuverlässig und ethisch vertretbar arbeiten, sollten Hochschulen standardisierte Spezifikationen für den Einsatz und klare Evaluationsprozesse entwickeln. Diese sollten regelmäßige Überprüfungen der Systeme beinhalten.
Vermittlung digitaler und ethischer Kompetenzen:
Die universitäre Bildung sollte nicht nur technische Fähigkeiten im Umgang mit generativer KI fördern, sondern auch ethische Reflexion und Verantwortungsbewusstsein. Studierende müssen lernen, die sozialen und ethischen Implikationen der generativen KI zu verstehen, um zukünftige Technologien verantwortungsvoll einsetzen zu können. (Christen et al., 2020; Bodmann & Wannemacher; 2021)

Abb. 3: Yutong Liu & Kingston School of Art / Better Images of AI / Talking to AI 2.0 / CC-BY 4.0
4.2. Schattenseiten des Einsatzes von KI
Die Entwicklung und der Einsatz von KI-Systemen eröffnen große Chancen und Potenziale, stellen uns aber auch vor Herausforderungen, die sorgfältiges Denken und Handeln erfordern. Für die Erkennung und Bewertung von KI-Ergebnissen sind Grundlagen wie der Umgang mit Fehlinformationen, gründliche Recherche sowie die Überprüfung von Aktualität und Konsistenz notwendig (Dreyer et al., 2023). Bei der Integration von KI in der Hochschullehre erfordern Aspekte wie Bias, die Arbeitsbedingungen der Menschen hinter den Modellen, der Ressourcenverbrauch sowie mangelnde Transparenz eine ganzheitliche Betrachtung. Letztere werden nun kurz dargestellt. Klicken Sie auf die Pfeile für mehr Informationen.
Bias
Durch das Training von KI-Modellen mit einseitigen und unvollständigen Datensätzen entsteht ein weitreichender Bias (engl. Vorurteil, Voreingenommenheit). Die Vielfalt von verschiedenen Kulturen, Geschlechtern und sozialen Gruppen sind somit in den riesigen Daten-Sätzen nicht angemessen abgebildet. Die Überrepräsentation bestimmter Quellen führt dazu, dass KI-Modelle in ihrem Output bestimmte Gruppen und Perspektiven bevorzugen und die Vielfalt und Komplexität der Gesellschaft nicht angemessen repräsentiert wird.
Diese Datengrundlagen spiegeln oft westliche und patriarchale Perspektiven wider, was zu einer Marginalisierung bestimmter Gesellschaftsgruppen und bestimmten Perspektiven führt.
Beispiele zeigen, dass die Modelle existierende Vorurteile und Stereotype nicht nur reproduzieren, sondern diese sogar aktiv verstärken und menschliches Verhalten nachhaltig beeinflussen können.
Dieser Bias zeigt sich aktuell in verschiedenen Bereichen - von Fällen geschlechtsspezifischer Gewalt, im Output von generativen KI-Modellen über stereotype Darstellungen von Ärzt*innen und anderen Berufsgruppen bis hin zu rassistischen Ratschlägen und das Erzeugen menschenverachtender Inhalte (Ahmad & Staiger, 2024).

Coded Bias - Wie wird KI rassistisch? (Klicken Sie auf den Link, um das Video zu starten.)
Video 7: Coded Bias - Wie wird KI rassistisch? Shalini Kantayya, 2021.
Video 8: KI und Bias | Vorurteile in der KI. Absolute Software, 2024.
KI-Halluzinationen
KI-Halluzinationen beziehen sich auf von KI-Modellen generierte Inhalte, die realistisch erscheinen, aber von den tatsächlichen Informationen abweichen. Dies bedeutet, dass die generierten Inhalte entweder nicht mit den ursprünglichen Eingabedaten übereinstimmen (faithfulness) oder faktisch nicht korrekt sind (factualness). Dies kann zu unbeabsichtigten Fehlinformationen führen. Solche Halluzinationen entstehen dadurch, dass KI-Modelle Texte basierend auf Wahrscheinlichkeiten generieren – sie berechnen also statistisch plausible Fortsetzungen eines Textes, was jedoch zu inhaltlichen Fehlern führen kann (Siebert 2024, Wellner 2025).
Weitere Gründe für KI-Halluzinationen:
- Fehlerhafte oder unvollständige Traininsgdaten: Wenn die Daten, mit denen das Modell trainiert wird, unvollständig oder fehlerhaft sind, kann das Modell falsche Muster lernen und Halluzinationen erzeugen. Dies kann passieren, wenn die Daten nicht aktuell sind oder bestimmte Themen nicht ausreichend abdecken - etwa wenn es medizinische Informationen verwendet, die nicht den neuesten wissenschaftlichen Standards entsprechen.
- Probleme bei der Informationsverarbeitung: Die Art und Weise, wie KI-Modelle Informationen verarbeiten, kann zu Fehlern führen. Beispielsweise können sie sich zu sehr auf bestimmte Teile des Kontexts konzentrieren und den Gesamtzusammenhang aus den Augen verlieren.
Um mögliche Nachteile durch KI-Halluzinationen zu minimieren, sollten Nutzerinnen folgende Empfehlungen beachten:- Bleiben Sie kritisch und hinterfragen Sie Informationen
- Nutzen Sie generative KI als Unterstützung, nicht als alleinige Informationsquelle
- Geben Sie klare und präzise Anweisungen, wenn Sie generative KI-Tools verwenden (siehe Kapitel 2 „Was ist Prompting?“)
KI-Halluzinationen können durch sorgfältigere Aufbereitung der Trainingsdaten, verbesserte Modellarchitekturen und den Einsatz von Techniken wie der Verknüpfung mit externen Wissensdatenbanken reduziert werden. Es ist wichtig, dass Nutzer*innen und Entwickler*innen kritisch bleiben und die Grenzen von KI-Systemen verstehen (ebd.).
Video 9: Warum KI DICH anlügt: KI-Halluzinationen einfach erklärt. cloudstrive, 2024.
Moral & Empathie: Die Menschen hinter den Modellen
Entgegen der Annahme einer vollständigen Automatisierung benötigen KI-Modelle - insbesondere für ihr Training - in der Realität präzise Unterstützung durch menschliche Arbeitskräfte. Technologieunternehmen greifen häufig auf günstigere Arbeitskräfte in Ländern mit geringem bzw. keinem Arbeitnehmer*innenschutz zurück, um Daten zu labeln und KI-Ergebnisse zu verifizieren.
Am Beispiel von OpenAI wird dies deutlich: Das Unternehmen beschäftigte Arbeiter*innen in Kenia, die weniger als 2 US-Dollar pro Stunde verdienten. Ihre Aufgabe war es, besonders gefährliche Inhalte wie z.B. Darstellungen sexualisierter Gewalt herauszufiltern. Die Arbeiter*innen sahen sich dabei traumatisierenden Inhalten ausgeliefert und beschrieben ihre Arbeitsbedingungen als "Folter".
Die globale Arbeitsteilung in der KI-Branche spiegelt bestehende wirtschaftliche Ungleichheiten wider: Während Unternehmen in wohlhabenden Regionen des Globalen Nordens, wie den USA und Deutschland die hoch qualifizierte und gut bezahlte KI-Entwicklung vorantreiben, wird die arbeitsintensive, ethisch herausfordernde und deutlich schlechter bezahlte Datenannotation und -bereinigung an Arbeitskräfte in Ländern wie Indien, Uganda oder Kenia ausgelagert. Diese Praxis verstärkt die wirtschaftliche Ungleichheit, da die Menschen, die diese grundlegende Arbeit verrichten, meist im Globalen Süden, kaum vom technologischen Fortschritt profitieren, den sie mit ermöglichen. Die Frage nach fairen Arbeitsbedingungen im KI-Training bleibt offen. Es zeigen sich erste Gegenbewegungen wie die Gründung einer Gewerkschaft in Kenia (Ahmad & Staiger, 2024).
Ökologische Schattenseiten
Die Entwicklung und der Einsatz von KI-Modellen werden oft nur aus technologischer Sicht betrachtet, wobei der massive Ressourcenverbrauch vernachlässigt wird. Tatsächlich haben der enorme Wasserverbrauch, die benötigten Rohstoffe und der hohe Energiebedarf für die Herstellung und den Betrieb der benötigten Hardware erhebliche Auswirkungen auf die Umwelt (Ahmad & Staiger, 2024):
- Der Betrieb von ChatGPT im März 2024 verbrauchte rund 700.000 Liter Frischwasser und so viel Energie wie 180.000 US-Haushalte (z.B. zur Kühlung der Rechenzentren).
Die Generierung eines KI-Bildes verbraucht so viel Energie wie eine volle Handyladung.
-
Für die Kühlung der Google-Rechenzentren in den USA wurde 2021 rund 12,7 Milliarden Liter Frischwasser benötigt.
-
Bei jeder ChatGPT-Anfrage wird zehnmal soviel Energie verbraucht wie bei einer Google-Suche (Weiß, 2024).
-
Für die Herstellung der benötigten Hardware werden seltene Rohstoffe und Metalle benötigt. Der Abbau und die Verarbeitung dieser Materialien verursachen zusätzliche Umweltbelastungen und ökologische Schäden.
- Das Training eines Sprachmodells verursacht etwa so viele Emissionen wie fünf Autos über ihren gesamten Lebenszyklus.
Konkrete Daten zum Ressourcenverbrauch von KI-Modellen fehlen jedoch, da Unternehmen häufig nicht transparent über ihren Energie- und Wasserverbrauch sowie ihre Emissionen berichten. Ähnlich wie bei den Trainingsdaten (siehe unten) ist mehr Transparenz erforderlich, um wirksame Maßnahmen zur Verringerung der Umweltauswirkungen zu entwickeln. Mögliche Lösungsansätze sind sparsamere Modelle, effizientere Rechenzentren und mögliche gesetzliche Vorgaben zur Offenlegung des Ressourcenverbrauchs und zur umweltfreundlicheren Entwicklung und Nutzung von KI-Systemen (Ahmad & Staiger, 2024).
Video 10: Energiebedarf und KI: Der Stromverbrauch hinter ChatGPT & Co. Technic Journal, 2024.
Transparenz
Die mangelnde Transparenz bei KI-Trainingsdaten stellt ein ernsthaftes Problem dar. Viele KI-Unternehmen dokumentieren die Zusammensetzung ihrer Datensätze nicht ausreichend, was zu erheblichen Risiken und ethischen Bedenken führt. Diese Intransparenz hat mehrere negative Konsequenzen:
-
Verzerrungen (Bias) in den Daten zu adressieren,
-
Schädliche Inhalte können nur schwer oder gar nicht aus den Trainingsdatensätzen entfernt werden
-
Die Identifizierung urheberrechtlich geschützter Inhalte wird erschwert.
-
Die Nachvollziehbarkeit und Überprüfbarkeit von KI-Entscheidungen wird stark eingeschränkt (Ahmad & Staiger, 2024).
-
Wirksame Maßnahmen zur Verringerung der Umweltauswirkungen können kaum effizient entwickelt werden
Es ist wichtig, die bestehenden Herausforderungen zu erkennen und aktiv an Lösungen zu arbeiten, um die Integration so effektiv wie möglich zu gestalten. Die Zusammenarbeit zwischen Studierenden und Lehrenden erfordert gegenseitiges Verständnis, Kommunikation und Flexibilität, um den Anforderungen gerecht zu werden und die Vorteile der Technologie voll auszuschöpfen (Gregor, 2023).
5. Weiterführende Literatur und Quellen
Dieses Kapitel enthält das Literatur- sowie das Abbildungs- und Videoverzeichnis.
5.1. Literaturverzeichnis
- Ahmad; Staiger (2024): Das Ökosystem der KI-Basismodelle: Wie Daten, Energie und menschliche Arbeit KI-Basismodelle formen, [online] https://www.reframetech.de/wissensseite-basismodelle/ [abgerufen am 29.07.2025].
- Bohr; Daum; Schulze-Bentrop (2023): Die Argumentationsfähigkeit. der Studierenden mit Hilfe von KI-Schreibtools entwickeln. Blogbeitrag in: Hochschulforum Digitalisierung [online] https://www.vkkiwa.de/blog/die-argumentationsfaehigkeit-der-studierenden-mit-hilfe-von-ki-schreibtools-entwickeln/ [abgerufen am 29.07.2025].
- Bodmann; Wannemacher (2021): Künstliche Intelligenz an den Hochschulen - Potenziale und Herausforderungen in Forschung, Studium, Lehre und Curriculumentwicklung. Hochschulforum Digitalisierung, [online] https://hochschulforumdigitalisierung.de/sites/default/files/dateien/HFD_AP_59_Kuenstliche_Intelligenz_Hochschulen_HIS-HE.pdf [29.07.2025].
- Christen; Mader; Čas et al. (2020). Wenn Algorithmen für uns entscheiden: Chancen und Risiken der künstlichen Intelligenz. (TA-SWISS 72). Zürich: vdf Hochschulverlag, [online] https://www.zora.uzh.ch/id/eprint/188444/1/4002_Wenn-Agorithmen-fuer-uns-entscheiden_OA.pdf [abgerufen am 29.07.2025].
- Chat GPT 3.5 (2023): ChatGPT, [online] https://chat.openai.com [abgerufen am 17.10.2024].
- Delua (2021): Supervised vs. unsupervised learning: What’s the difference? IBM Blog [online] https://www.ibm.com/think/topics/supervised-vs-unsupervised-learning [abgerufen am 29.07.2025].
- Deuring (2022): Mit KI den barrierefreien Zugang zu Dokumenteninhalten ermöglichen - CIB Group [online] https://www.cib.de/barrierefreiheit-mit-ki-den-zugang-zu-dokumenteninhalten-ermoeglichen/ [abgerufen am 29.07.2025].
- DGSVO, Personenbezogene Daten (2024): https://dsgvo-gesetz.de/themen/personenbezogene-daten/ [abgerufen am 29.07.2025].
- Dreyer, Schürmann Rosenthal/Schürmann Rosenthal Dreyer Rechtsanwälte (2020): Künstliche Intelligenz & Ethik: Zwischen Potenzial und Risiken, Schürmann Rosenthal Dreyer Rechtsanwälte, [online] https://www.srd-rechtsanwaelte.de/blog/kuenstliche-intelligenz-ethik/ [abgerufen am 29.07.2025].
- Gimpel et al: UNLOCKING THE POWER OF GENERATIVE AI MODELS AND SYSTEMS SUCH AS GPT-4 AND CHATGPT FOR HIGHER EDUCATION. Hohenheim Discussion Papers in Business, Economics and Social Sciences. [online] https://wiso.uni-hohenheim.de/fileadmin/einrichtungen/wiso/Forschungsdekan/Papers_BESS/dp_2023-02_online.pdf [abgerufen am 29.07.2025].
- Gregor (2023): KI in der Hochschullehre: Herausforderung und Chance, Newsportal - Ruhr-Universität Bochum, [online] https://news.rub.de/studium/2023-09-04-experteninterview-ki-der-hochschullehre-herausforderung-und-chance [abgerufen am 29.07.2025].
- Bomke (2023): Handelsblatt [online] https://www.handelsblatt.com/technik/ki/glossar-acht-ki-begriffe-die-ihnen-auch-im-alltag-begegnen/29431606.html [abgerufen am 29.07.2025].
- Haverkamp; Schindler (2023): Künstliche Intelligenz in der Schule – grundlegende Überlegungen und Praxisbeispiele, Carl Link Verlag. Kluwer Wolters Online [online] https://research.wolterskluwer-online.de/document/b14af28e-a1eb-3937-a68d-39672b38b651 [abgerufen am 29.07.2025].
- Henrix; Ruschin (2023): KI in der Hochschullehre – Gekommen um zu bleiben, in: Magazins NIU, Eine hochschuldidaktische Beilage, Nr. 04 [online] https://www.hs-niederrhein.de/fileadmin/dateien/hll/hochschuldidaktik/LeNi-Beilage_in_der_NIU/Le_Ni_Beilage_4_KI_in_der_Hochschullehre_Gekommen_um_zu_bleiben.pdf [abgerufen am 29.07.2025].
- Koleva (2023): Die kreative Kraft der Maschinen entfesseln: Generative KI, Large Language Models und die Zukunft der Contenterstellung, [online] https://simpleshow.com/de/blog/generative-ki-large-language-models-zukunft-contenterstellung/ [abgerufen am 29.07.2025].
- Krebs (2022) Hochschule Braunschweig: Ethische Probleme beim Einsatz von Künstlicher Intelligenz im Gesundheitswesen, [online] https://opus.ostfalia.de/frontdoor/deliver/index/docId/1279/file/Hamza_2021_KI_Gesundheitswesen.pdf [abgerufen am 29.07.2025].
- KI-Campus (2023): Generative KI in 2 Minuten erklärt, [YouTube] https://www.youtube.com/watch?v=mxP3G2Jb2LM [abgerufen am 29.07.2025].
- Klein (2023): Was KI-Hasen und Karten mit der Literaturrecherche zu tun haben, UNIDIGITAL.news, [online] https://www.unidigital.news/was-ki-hasen-und-karten-mit-der-literaturrecherche-zu-tun-haben/ [abgerufen am 29.07.2025].
- Krutzfeldt (2023): Wie funktioniert Machine Learning: Arten & Einsatzgebiete 2023, stackfuel.com, [online] https://stackfuel.com/de/blog/machine-learning-algorithmen-data-analytics/ [abgerufen am 29.07.2025].
- Kulkarni; Adarsha; Kulkarni; Gudivada (2023): Applied Generative AI for Beginners - Practical Knowledge on Diffusion Models, ChatGPT, and Other LLMs. Apress.
- Mörth; Riedel (2023): Künstliche Intelligenz KI in der Hochschule, Lehre und Forschung [online] https://www.tu.berlin/bzhl/ressourcen-fuer-ihre-lehre/ressourcen-nach-themenbereichen/ki-in-der-hochschullehre [abgerufen am 29.07.2025].
- Fraunhofer-Institut für Kognitive Systeme IKS (2023): Künstliche Intelligenz in der Medizin, [online] https://www.iks.fraunhofer.de/de/themen/kuenstliche-intelligenz/kuenstliche-intelligenz-medizin.html [abgerufen am 29.07.2025].
- Leschke; Salden (2023): DIDAKTISCHE UND RECHTLICHE PERSPEKTIVEN AUF KI-GESTÜTZTES SCHREIBEN IN DER HOCHSCHULBILDUNG [online] https://doi.org/10.13154/294-9734 [abgerufen am 29.07.2025].
- Luber (2023): Was ist generative AI?, in: BigData-Insider, 15.05.2023, [online] https://www.bigdata-insider.de/was-ist-generative-ai-a-2ec9ecd5c114d4c94c48ea7092ec45ad/ [abgerufen am 29.07.2025].
- Lutkevich (2023): KI-Halluzination, ComputerWeekly.de, [online] https://www.computerweekly.com/de/definition/KI-Halluzination [abgerufen am 29.07.2025].
- McFarland (2023): Die 10 besten KI-Tools für die Bildung, Unite.AI, [online] https://www.unite.ai/de/Die-10-besten-KI-Tools-f%C3%BCr-den-Bildungsbereich/ [abgerufen am 29.07.2025].
- Mascellino (2023): KI-Prompts schreiben: ChatGPT, Bard, Bing und Co mit Beispielen, techopedia, [online] https://www.techopedia.com/de/how-to/ki-prompts-schreiben-anleitung [abgerufen am 18.11.2024].
- NineTwoThree (2023): Benefits of generative AI in user interactions, [online] https://www.ninetwothree.co/blog/benefits-of-generative-ai-in-user-interactions [abgerufen am 29.07.2025].
- Nopp (2019): Künstliche Intelligenz – Eine überblicksartige Darstellung innovativer Geschäftsmodelle, Bachelorarbeit, Johannes Kepler Universität Linz.
- Rieth; Hagemann (2021): Veränderte Kompetenzanforderungen an Mitarbeitende infolge zunehmender Automatisierung – eine Arbeitsfeldbetrachtung, in: Gruppe. Interaktion. Organisation. Zeitschrift für Angewandte Organisationspsychologie (GIO), Bd. 52, Nr. 1, S. 37–49, [online] https://link.springer.com/article/10.1007/s11612-021-00561-1 [abgerufen am 29.07.2025].
- Röhler et al. (2020) (Hrsg: VDMA Bayern): Leitfaden Künstliche Intelligenz – Potenziale und Umsetzungen im Mittelstand, [online] https://www.vdma.org/documents/34570/4617618/VDMA+Bayern_Leitfaden_KI_2020.pdf/0d21791b-4ee5-e881-8413-c6bfd2433327?t=1616089127402 [angerufen am 29.07.2025].
- Schäfer (2023): Prompts für KI - Definition und Beispiele für ChatGPT & MidJourney, Konfuzio, [online] https://konfuzio.com/de/prompts/ [abgerufen am 29.07.2025].
- Schmid (2022): Künstliche Intelligenz, [online] https://www.bidt.digital/glossar/kuenstliche-intelligenz/ [abgerufen am 29.07.2025].
- Siebert (2024): Halluzinationen von generativer KI und großen Sprachmodellen (LLMs), [online] https://www.iese.fraunhofer.de/blog/halluzinationen-generative-ki-llm/ [abgerufen am 29.07.2025].
- Stadler (2023): Künstliche Intelligenz, mindsquare, [online] https://mindsquare.de/knowhow/kuenstliche-intelligenz/ [abgerufen am 29.07.2025].
- IBS Technology (2021): Künstliche Intelligenz in Unternehmen – erste Schritte [online] https://www.ibs-technology.com/thema/kuenstliche-intelligenz-in-unternehmen-erste-schritte/ [abgerufen am 29.07.2025].
- Technische Hochschule Würzburg Schweinfurt (2024): Schwache vs. Starke KI – eine Definition [online] https://ki.thws.de/thematik/starke-vs-schwache-ki-eine-definition/ [abgerufen am 29.07.2025].
- Toepel (2019): Mit KI Mehr Individualisierung in der Hochschule Wagen | MMB Institut GmbH, [online] https://www.mmb-institut.de/ki-edtech/mit-ki-mehr-individualisierung-in-der-hochschule-wagen/ [abgerufen am 29.07.2025].
- von Garrel; Mayer; Mühlfeld (2023): Künstliche Intelligenz im Studium : Eine quantitative Befragung von Studierenden zur Nutzung von ChatGPT & Co., Hochschule Darmstadt. [online] https://opus4.kobv.de/opus4-h-da/frontdoor/index/index/docId/395 [abgerufen am 29.07.2025].
- Witt; Rampelt; Pinkwart (2020): Künstliche Intelligenz in der Hochschulbildung. KI-Campus. White Pape, [online] https://ki-campus.org/sites/default/files/2020-10/Whitepaper_KI_in_der_Hochschulbildung.pdf [abgerufen am 29.07.2025].
- Winter (2023): Enhance your writing with AI – Boost your writing results, SEOwind, [online] https://seowind.io/de/verbessere-deine-schrift-mit-ai/ [abgerufen am 29.07.2025].
- Weiß (2024): ChatGPTs Stromverbrauch: Zehnmal mehr als bei Google, [online] https://www.heise.de/news/ChatGPTs-Stromverbrauch-Zehnmal-mehr-als-bei-Google-9852126.html [abgerufen am 29.07.2025].
- Wellner, (2025): Die Rolle der Tonalität von generativer KI bei der Verbreitung und Wahrnehmung von Informationen. In: API Magazin 6(1) [Online] https://journals.sub.uni-hamburg.de/hup3/apimagazin/article/view/219/245 [abgerufen am 29.07.2025].
- Weßels (2022): ChatGPT – ein Meilenstein der KI-Entwicklung. Blogbeitrag in: Hochschulforum Digitalisierung [online] https://www.forschung-und-lehre.de/lehre/chatgpt-ein-meilenstein-der-ki-entwicklung-5271 [abgerufen am 29.07.2025].
- Weßels; Mundorf; Wilder (2022): ChatGPT ist erst der Anfang. Blogbeitrag in: Hochschulforum Digitalisierung [online] https://hochschulforumdigitalisierung.de/blog/chatgpt-ist-erst-der-anfang/ [abgerufen am 29.07.2025].
- Wuttke (2023): Machine Learning vs. Deep Learning: Wo ist der Unterschied?, datasolut GmbH, [online] https://datasolut.com/machine-learning-vs-deep-learning/ [abgerufen am 29.07.2025].
5.2. Abbildungs- und Videoverzeichnis
Abbildungen
- Abb 1: Hanna Barakat & Cambridge Diversity Fund / Better Images of AI / Data Lab Dialogue / CC-BY 4.0
- Abb. 2: Komponenten der KI. Nach: Introduction to Generative AI, Apress, Seite 3. Applied Generative AI for Beginners. Kulkarni et al, 2023.
- Abb. 3: Yutong Liu & Kingston School of Art / Better Images of AI / Talking to AI 2.0 / CC-BY 4.0
Videos
- Video 1: Eine kurze Geschichte der KI. Lernende Systeme, die Plattform für Künstliche Intelligenz, 2020. https://img.youtube.com/vi/09LotPHTZtU/maxresdefault.jpg [abgerufen am 12.08.25]
- Video 2: Was ist Künstliche Intelligenz genau? Unterschiede zwischen starker KI und schwacher KI erklärt. Digitalzentrum Berlin, 2021.https://youtu.be/NhnGtVjRScI?si=kFgag14G6W07u-qc [abgerufen am 12.08.25]
- Video 3: Machine Learning. darasolut, 2023. https://youtu.be/n9lGYJkBLTA?si=cV3ExuYd1cN81550 [abgerufen am 12.08.25]
- Video 4: Was ist generative KI? https://youtu.be/mxP3G2Jb2LM?si=Hnvyps1lswaNPtSS [abgerufen am 12.08.25]
- Video 5: Was ist ChatGPT? https://youtu.be/9PUh6mKkq4w?si=2QiEZSxc2XGBgteL [abgerufen am 12.08.25]
- Video 6: Die 5 besten Prompt Engineering Tipps in nur 5 Minuten. Quelle: Datasolut, 2024. https://www.youtube.com/watch?v=A18IyZnEP_4 [abgerufen am 12.08.25]
- Video 7: Coded Bias - Wie wird KI rassistisch? Shalini Kantayya, 2021. https://www.dw.com/de/coded-bias-wie-wird-ki-rassistisch/video-57018426 [abgerufen am 12.08.25]
- Video 8: KI und Bias | Vorurteile in der KI. Absolute Software, 2024. https://youtu.be/4oEHMnIUlP4?si=VD9IrYTa5QJTNbfQ [abgerufen am 12.08.25]
- Video 9: Warum KI DICH anlügt: KI-Halluzinationen einfach erklärt. cloudstrive, 2024. https://youtu.be/cumYLnkXJ-I?si=xTVVI2pRWUi6VgvX [abgerufen am 12.08.25]
- Video 10: Energiebedarf und KI: Der Stromverbrauch hinter ChatGPT & Co. Technic Journal, 2024. https://youtu.be/fOutLOiFJhw?si=4t9TOZCR5mtSnXPy [abgerufen am 12.08.25]
6. Lizenzangaben und Nachnutzung
Die Inhalte dieses Lernmoduls sind u.a. in Anlehnung an die Selbstlerneinheit "Wie kann ich KI gewinnbringend in die Lehre integrieren?" von Yasmin Peters nach der "CC-BY-SA 4.0"- Lizenz entstanden. Einige Text-Passagen wurden in Unterstützung mit generativen KI-Modellen überarbeitet.
Die Weiternutzung als OER ist ausdrücklich erlaubt: Dieses Werk und dessen Inhalte sind - sofern nicht anders angegeben - lizenziert unter CC BY-SA 4.0. Nennung gemäß TULLU-Regel bitte wie folgt: Lernmodul: "Einführung in den Einsatz von generativen KI-Systemen / LLMs" von Hannah Baur, Abteilung E-Learning, Albert-Ludwigs-Universität Freiburg, Lizenz: CC BY-SA 4.0. Gekürzt, bearbeitet und ergänzt von Moodle.NRW | Jasmin vom Brocke, Valerie Hindenburg, Version 2.0, Lizenz CC BY-SA 4.0.